Problem Statement.
We aim to solve the problem of explaining the prediction of a deep neural network post-hoc using
high level human interpretable concepts. In this work, we blur the distinction of post-hoc
explanations and designing interpretable models.
Why post-hoc, not interpretable by design?
Most of the early interpretable by design methods focus on tabular data. Plus, they tend to be
less flexible than the Blackbox models and demand substantial expertise to design. Also, mostly
they underperform than their Blackbox counterparts. Post hoc methods preserve the
flexibility and performance of the Blackbox.
Why concept based model, not saliency maps?
Post-hoc based saliency maps identify key input features that contribute the most to
the network’s output. They suffer from a lack of fidelity and mechanistic explanation of the
network output. Without a mechanistic explanation, recourse to a model’s undesirable behavior
is unclear. Concept based models can identify the important concept, responsible for the
model's output. We can intervene on these concepts to rectify the model's prediction.
What is a concept based model?
Concept based model or technically Concept Bottleneck Models are a family of models where
first the human understandable concepts are predicted from the given input (images) and then the
class labels are predicted from the concepts. In this work, we assume to have the ground truth
concepts either in the dataset (CUB200 or Awa2) or discovered from another dataset (HAM10000,
SIIM-ISIC or MIMIC-CXR). Also, we predict the concepts from the pre-trained embedding of the
Blackbox as shown in Posthoc Concept Bottleneck
Models.
What is a human understandable concept?
Human understandable concepts are high-level features which constitute the class label. For
example, the stripes can be a human understandable concept, responsible for predicting zebra.
In chest-x-rays, anatomical features like lower left lobe of lung can be another human
understandable concept. For more details, refer to
TCAV paper or
Concept Bottleneck Models .
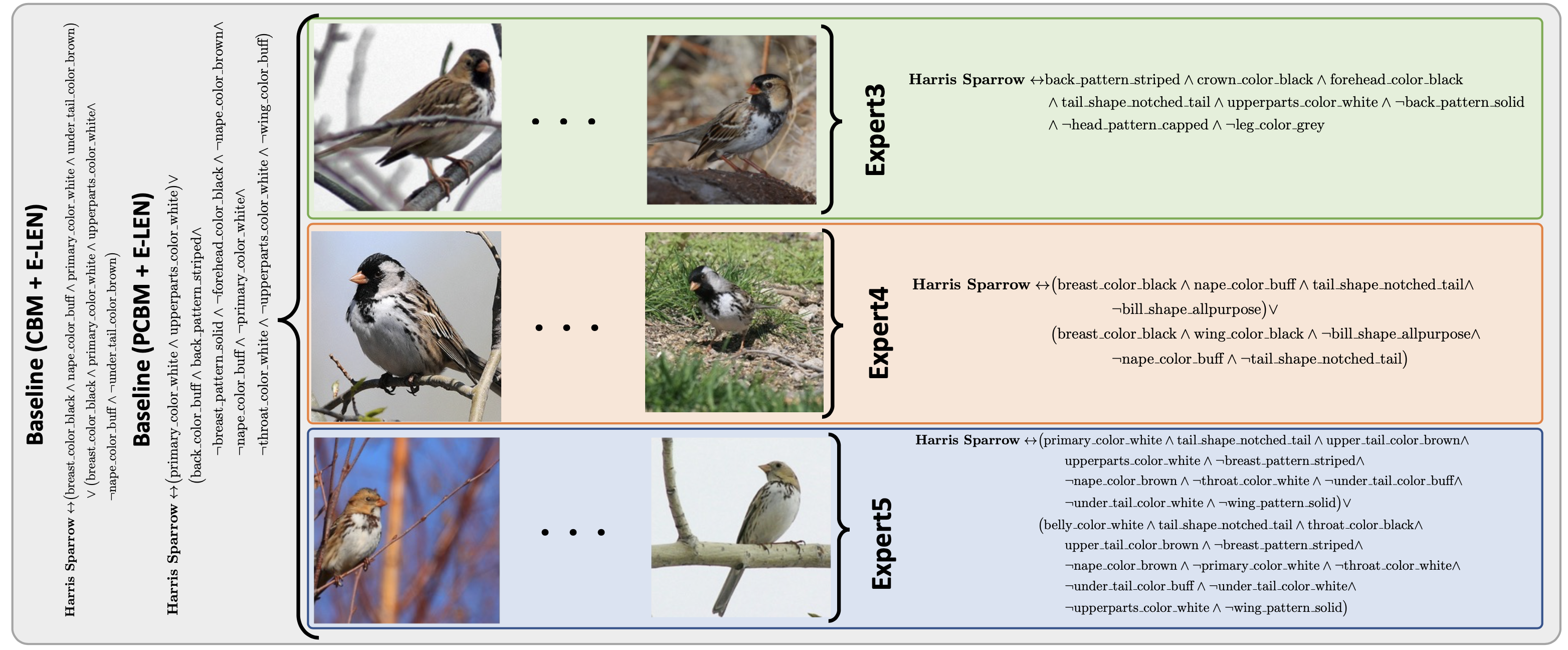
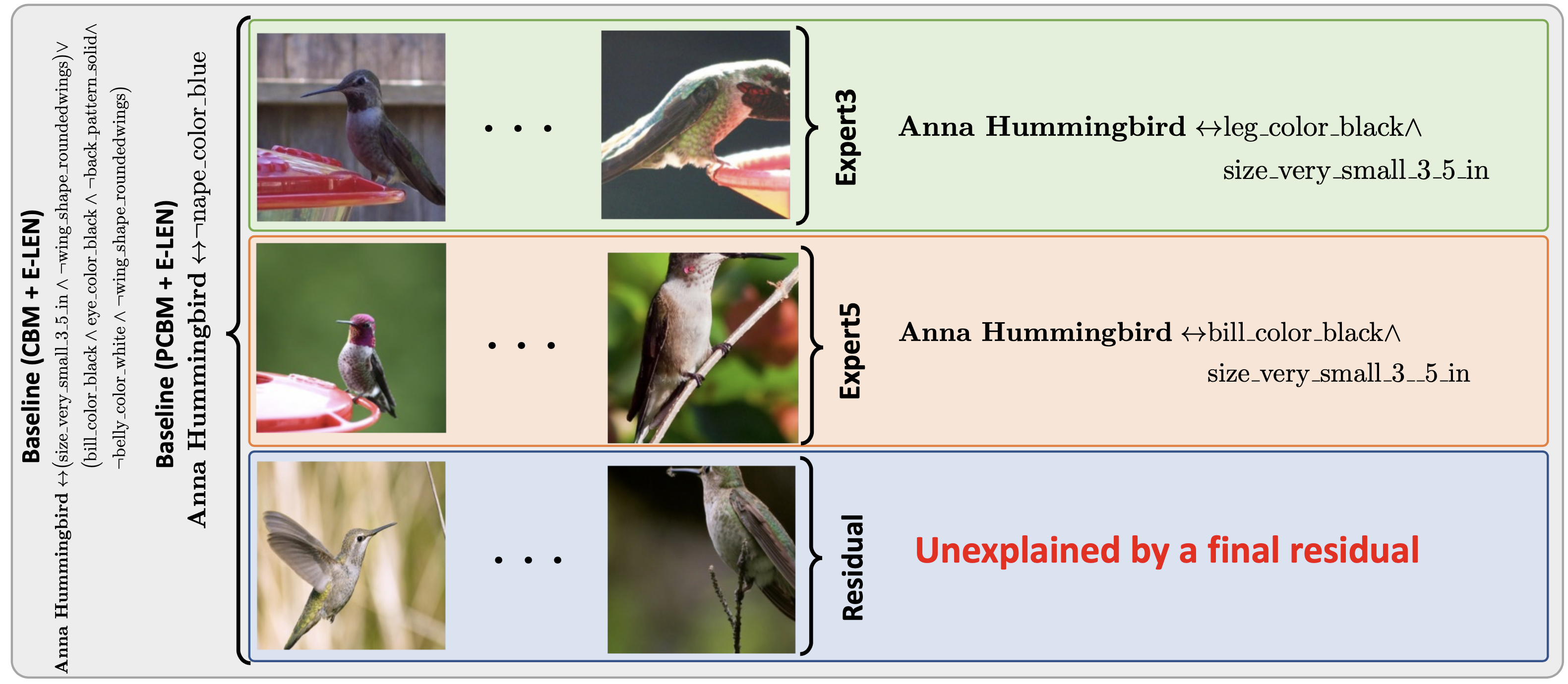
What is the research gap?
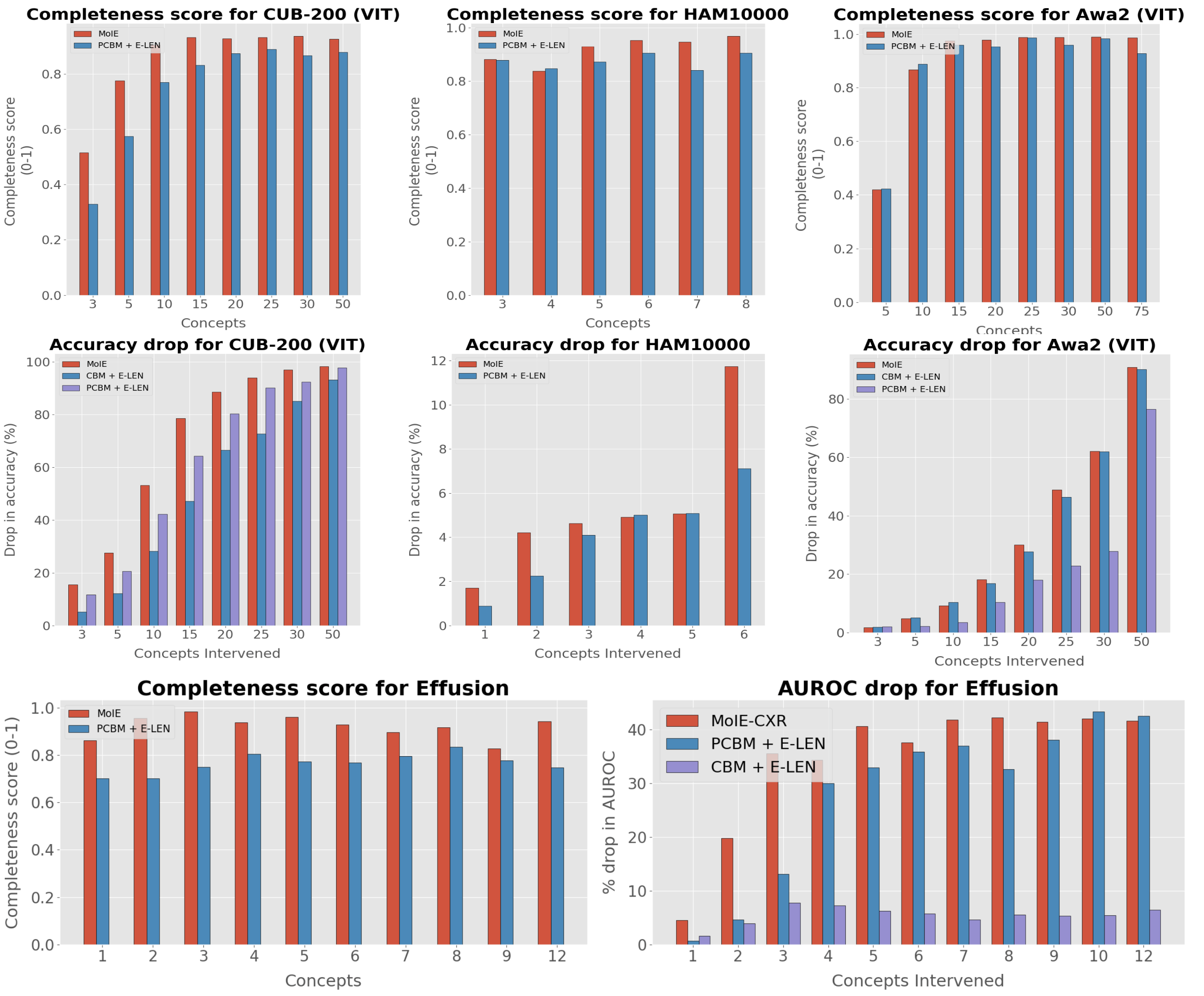
Most of the interpretable models (interpretable by design or post-hoc) utilizes a single
interpretable model to fit the whole data. If a portion of the data does not fit the template
design of the interpretable model, they do not offer any flexibility, compromising performance.
Thus, a single interpretable model may be insufficient to explain all samples, offering generic
explanations.
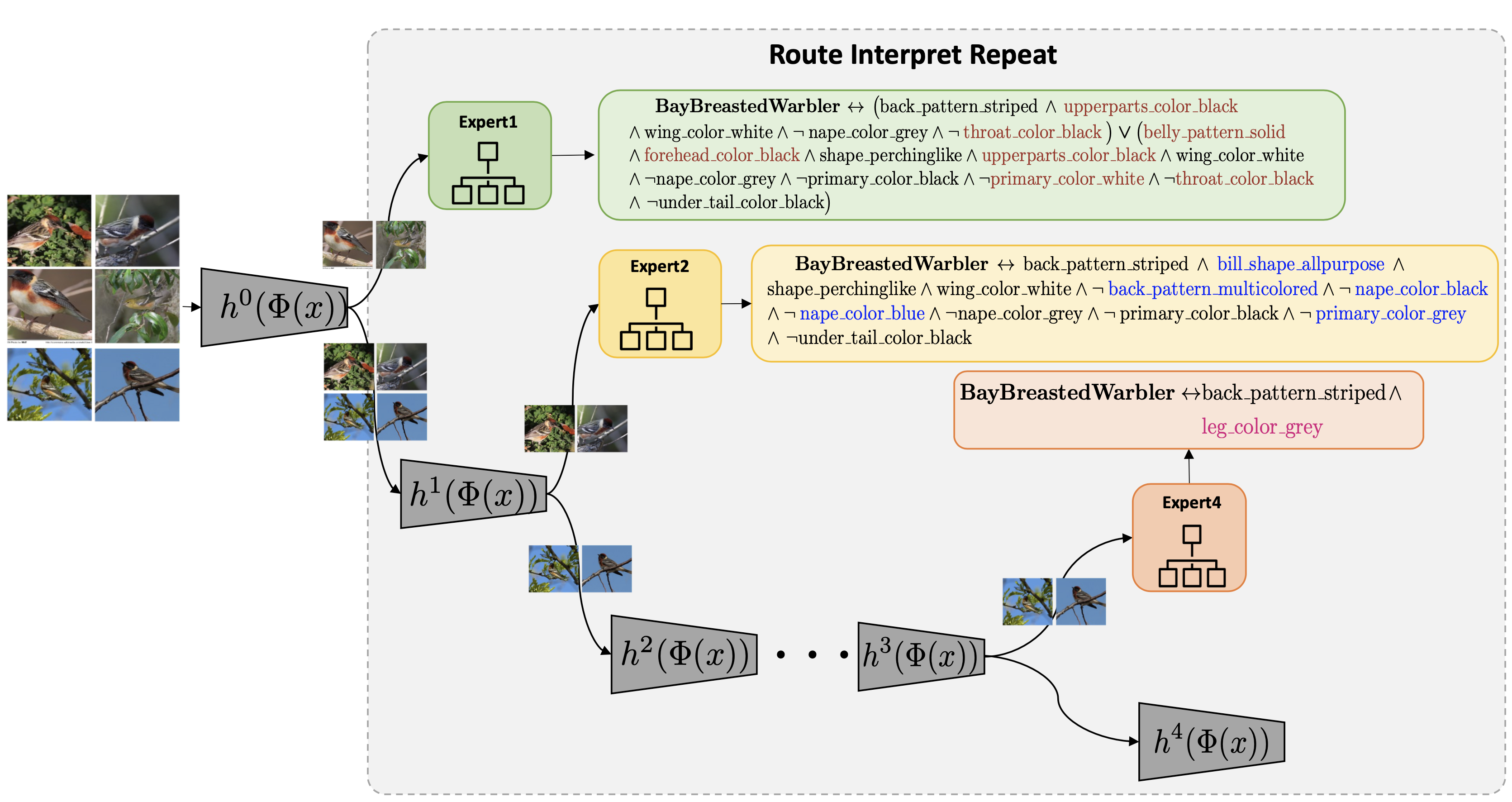
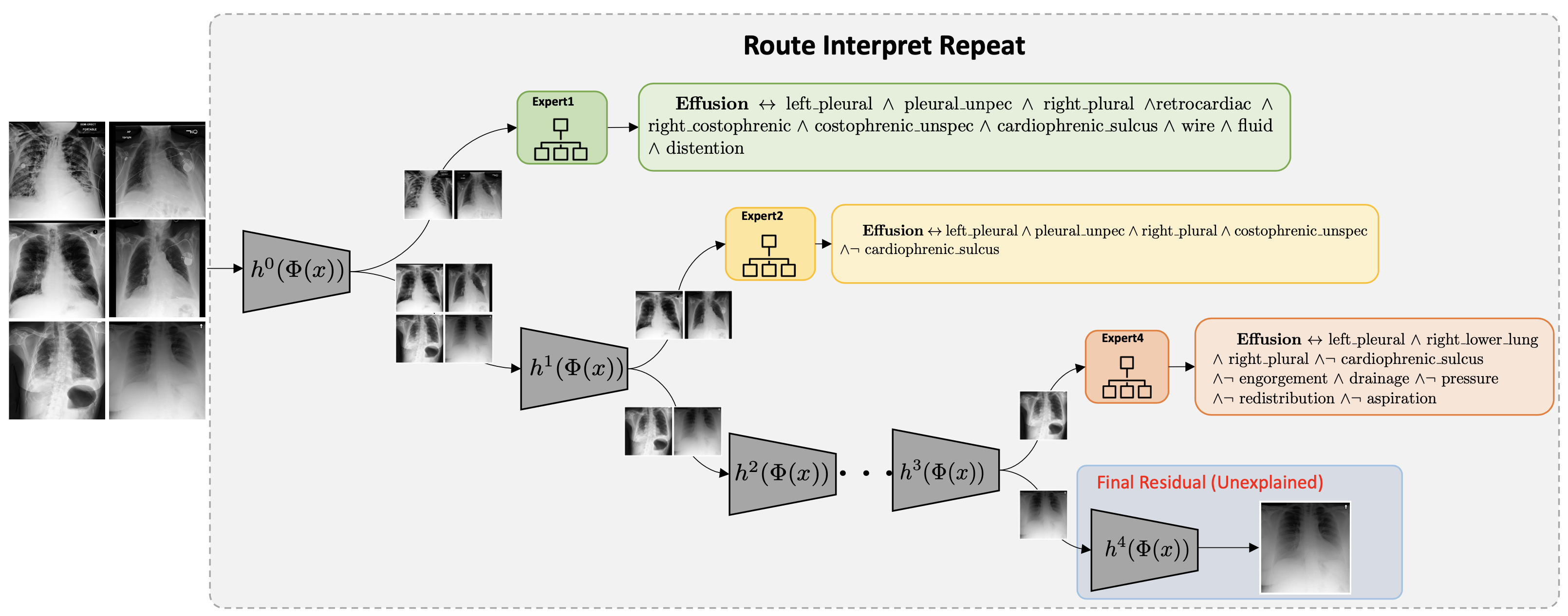
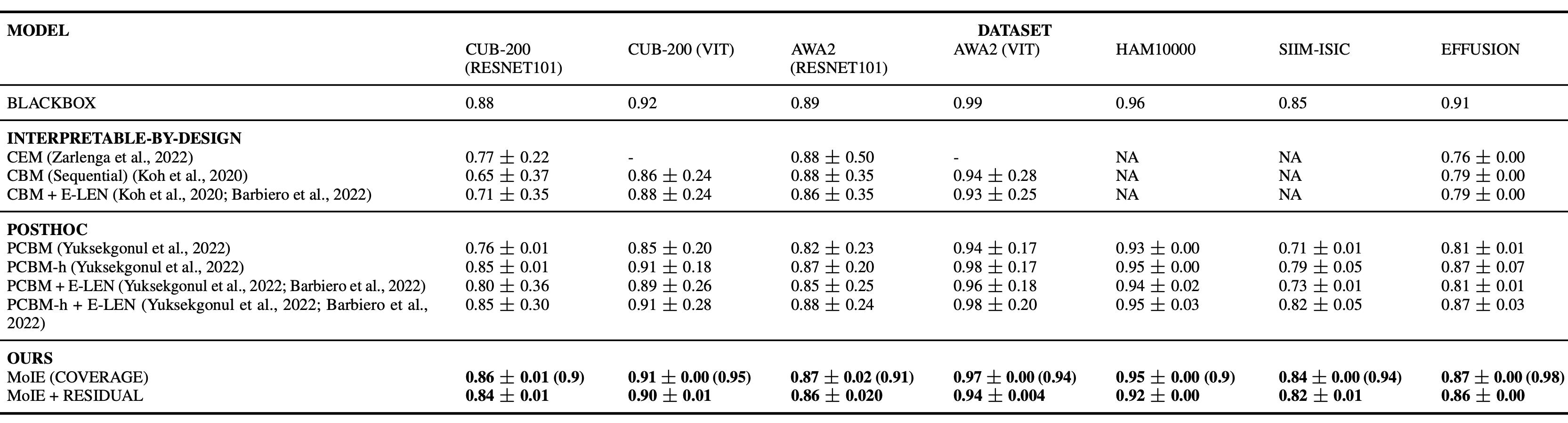
Our contribution.
We propose an interpretable method,
aiming to achieve the best of both worlds: not sacrificing
Blackbox performance similar to post hoc explainability
while still providing actionable interpretation. We hypothesize that a Blackbox encodes several
interpretable models,
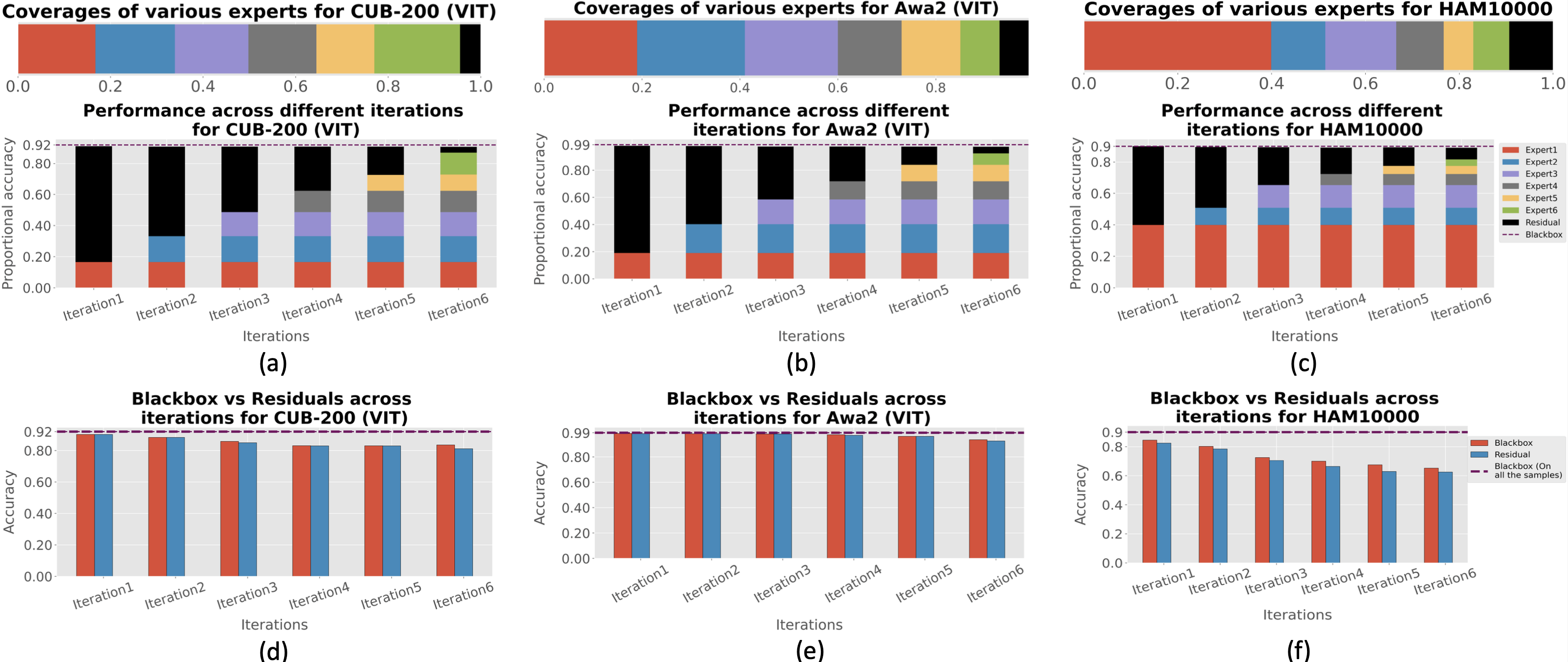
each applicable to a different portion of data. We construct a hybrid neuro-symbolic model by
progressively carving out a mixture of interpretable models
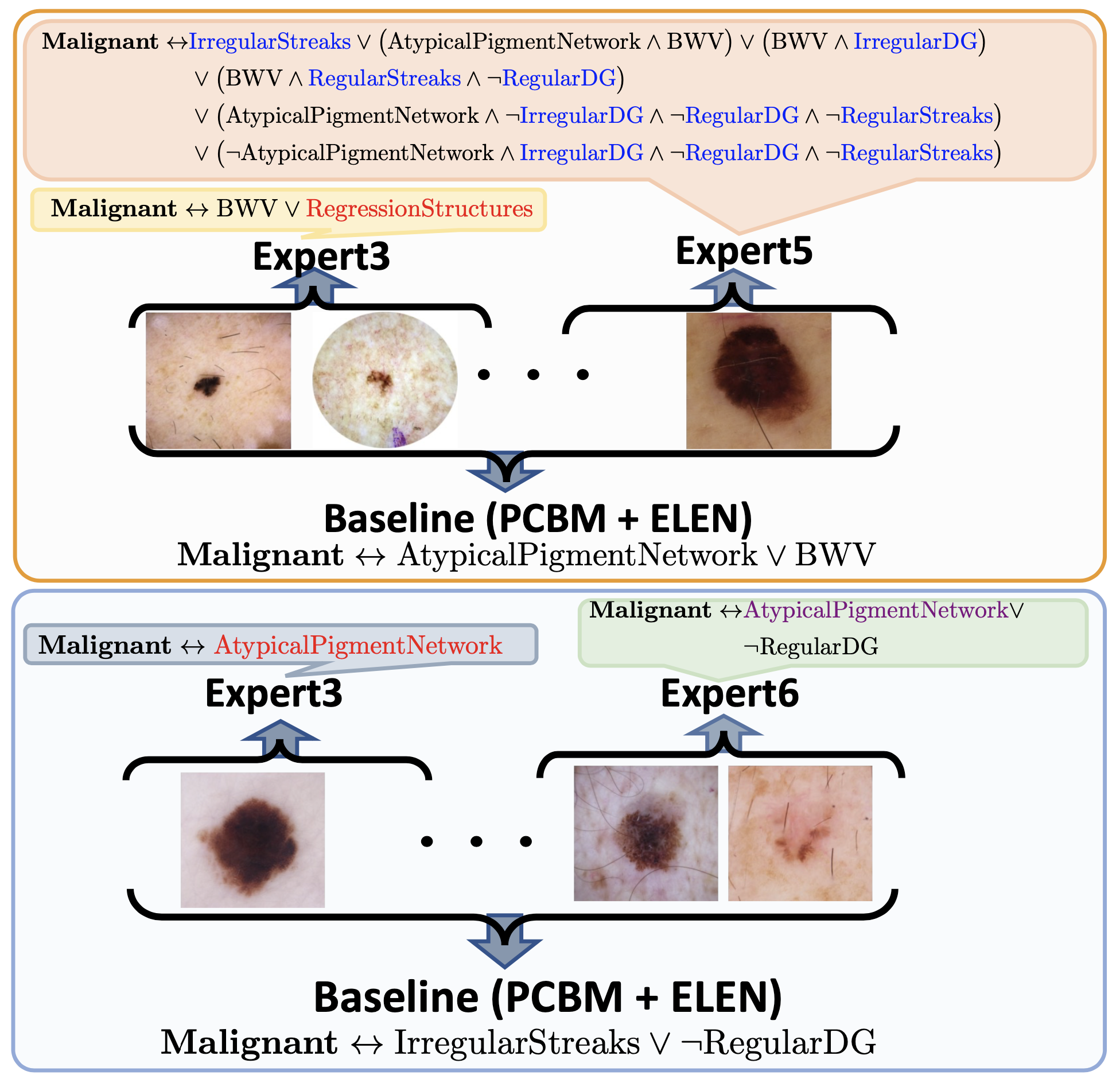
and a residual network from the given Blackbox. We coin
the term expert for each interpretable model, as they specialize over a subset of data. All the
interpretable models are
termed a Mixture of Interpretable Experts (MoIE). Our design identifies a subset of
samples
and routes them through
the interpretable models to explain the samples with First order logic(FOL),
providing basic reasoning on concepts from the Blackbox.
The remaining samples are routed through a flexible residual
network. On the residual network, we repeat the method
until MoIE explains the desired proportion of data. Using FOL for interpretable models
offers recourse when undesirable behavior is detected in the
model. Our method is the
divide-and-conquer approach, where the instances covered
by the residual network need progressively more complicated interpretable models. Such insight
can be used to
inspect the data and the model further. Finally, our model
allows unexplainable category of data, which is currently
not allowed in the interpretable models.
What is a FOL?
FOL is a logical function that accepts predicates (concept presence/absent) as input and returns
a True/False output being a
logical expression of the predicates. The logical expression, which is a set of AND, OR,
Negative, and parenthesis, can be
written in the so-called Disjunctive Normal Form (DNF). DNF is a FOL logical
formula composed of a
disjunction (OR) of conjunctions (AND), known as the sum of products.